一种基于分布式计算的疾病大数据挖掘分析系统
G16H50/00:专门用于医疗诊断,医学模拟或医疗数据挖掘的信息和通讯技术;专门适用于检测、监测或建模流行病或传染病。
场景分析
- 疾病大数据的数据类型
- 在疾病大数据的数据挖掘预处理中(数据清洗过程中)有什么场景特征
- 对疾病大数据进行数据清洗的过程中有什么适用的算法,算法中有什么问题
- 医疗机构间信息不连通,导致慢病患者在不同机构进行多次登记建档。此外,医疗机构是定时向卫生信息平台上传数据,相邻批次上传的数据可能存在小范围时间上的重叠,即存在部分业务记录多次重复出现。针对这些重复记录,现有的处理方式是只保留最早一次上传的记录,并删除其他重复记录。
- 对于不合理数据的修正,医疗记录中存在一些不合理的测量数值,如,收缩压取值为5。通过统计各数据项的取值分布,并以离散图或柱形图进行展示,通过观察定义取值区间,将区间之外的值看作缺失处理。主要处理的数据项包括SBP、DBP、BMI、心率、身高、体重、血糖等连续型变量。
-
在电子病历数据中提取到的高血压患者随访信息,通过特征提取与处理获取特征向量,并构建冠心病风险预测模型,从而对患有高血压的患者进行冠心病风险预测。其中特征提取与处理的过程为:
-
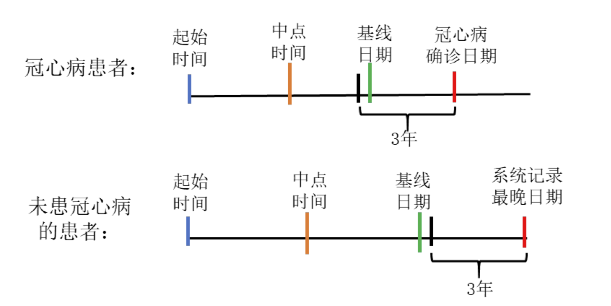
定义起始时间、结束时间、基线日期以及中点时间
- 起始时间:高血压患者确诊之后的首次医疗业务记录的日期。
- 结束时间:对于冠心病患者,结束时间定义为冠心病的确诊日期;对于未患有严重疾病的高血压患者,结束时间定义为系统记录的最晚日期,即随访记录、门诊记录以及住院记录中最晚一次记录的日期。
- 基线日期:评估患者冠心病发病风险的当前日期。对于冠心病患者,基线日期定义为结束时间之前三年内的最早一次随访记录的日期;对于未患严重疾病的高血压患者,基线日期定义为结束时间3年之前的最后一次随访记录的日期。
- 中点时间:定义为起始日期和基线日期的中间点。
-
结合已有研究成果和可用数据,主要从基本信息、门诊、住院、检验以及疾病管理这五类业务数据表中提取潜在的特征变量作为模型输入,具体包含:
-
基本信息:居民ID、性别、出生日期,其中居民ID是用于关联患者的各类业务记录。
-
高血压登记及随访记录:居民ID、高血压确诊日期、高血压患病年限,以及如下特征:
- 基线特征:基线日期、年龄、SBP、DBP、HR、BMI、空腹血糖(GLU)
- 趋势特征:分别提取基线日期之前、中点时间之前、中点时间之后的所有随访记录,得到随访次数,SBP、DBP、HR、BMI和GLU的最大值、最小值、均值等
-
门诊或住院信息:筛选出基线日期之前的门诊或住院信息,得到住院次数、住院总天数,并从诊断结果中提取出高血压等级、糖尿病、高血脂、高尿酸血症、肾部疾病、脑部疾病、肺部疾病、慢性胃炎、痛风、心律失常、睡眠障碍、头晕头痛、心悸等病症。病症都是二进制变量,患病为1,否则为0。
-
服药行为:从主要用药记录、门诊处方以及住院医嘱中,提取基线日期之前的服药信息,包括降压药、降糖药或胰岛素、降脂药三个类别。若患者服用过此类药物,则取值为1,否则为0。
-
生活行为:从个人生活行为记录中,提取基线日期之前的吸烟情况、饮酒情况。根据患者是否有某种行为,有为1,否则为0。
-
-
-
在数据挖掘的过程中需要对采集到的数据进行关联分析,重点是发现数据库中不同项之间的关系,找出数据集中的频繁模式和并发关系,频繁和并发关系即为关联。衡量关联规则强度的两个重要指标是支持度和置信度。
-
挖掘频繁项集的算法有很多,主要分为两类:候选生成方法和增长模式。其中Apriori算法是著名的关联规则挖掘算法,属于候选生成方法。其采用逐层迭代的方法挖掘频繁项。算法中的两个关键操作是连接步和剪枝步:
- 连接:为了寻找频繁
项集 ,算法需要执行 自连接操作,产生候选频繁项集 。 中的元素在前 个项都相同的情况喜爱,其中的元素就可以进行连接操作。 - 剪枝:通过扫描数据库,以确定候选
项集 中的候选项,进而确定 。产生 时,先对 剪枝,将不再 中的 项子集的 进行剪枝操作,降低 的大小,进而根据 中的候选项得出频繁 项集 。
- 连接:为了寻找频繁
-
Apriori算法存在的不足:
- 频繁项集的生成是需要反复扫描整个数据库的,当项集较大时,算法需要候选集中的每一个子集诸葛扫描匹配,这个过程会消耗大量的时间和空间,算法的适应性变差。
- 面对大型数据库,TB级甚至PB级的数据量,传统算法的串行计算方式面临着工作量和计算量巨大的难题,无法及时响应和处理,造成内存消耗大、执行效率低等情况的发生。
-
改进思路:
- 引入索引结构的改进Apriori算法,将数据通过Map Reduce分块,在分块中采用索引结构的执行模式,不需要对数据库进行多次扫描,并行执行算法,提高数据处理速度。63
- 基于兴趣度阈值,降低算法的时间复杂度。64
- 通过只扫描数据库中某些事务项来减少时间浪费,使得改进后的算法更有效率,减少时间消耗。65
- 利用矩阵理论改进Apriori算法,通过将算法的剪枝与矩阵连接起来,能够减少数据库的扫描时间,同时压缩搜索时间,降低计算成本,提高算法效率。66
兴趣度如何确定?如何通过兴趣度来让关联分析的过程计算更少?在疾病数据的背景中如何获取项集之间关联分析的兴趣度。
。
